機械学習 (ML)。アルゴリズムを使用した数学的モデルのトレーニング 多重線形回帰
![[多変量線形回帰]ボタン](https://advanced-quality-tools.ru/images/buttons/LinearRegression.png)
線形回帰は、線形依存関数を使用して、1 つの (説明済み、従属) 変数の別の変数または複数の他の変数 (因子、回帰変数、独立変数) への依存関係の統計に使用される回帰モデルです。
線形回帰は、一連の異なるデータ ポイントに最もよく適合する直線を決定するプロセスとして定義されます。この線を投影して、新しいデータ ポイントを予測できます。線形回帰はそのシンプルさと重要な機能により、機械学習の基本的な手法です。
いくつかの確率変数のセット (複数の独立変数を持つ 1 つの従属変数) に対するある確率変数の回帰依存関係を構築する場合、重線形回帰 (多重線形回帰) を構築することについて話します。独立変数が 1 つだけの場合、単純な線形回帰の構築について話します。
数学モデルを作成し、重線形回帰アルゴリズムで予測を行うための構造化スプレッドシート ファイルの例をダウンロードできます (このデータのサンプルは、回帰モデルのデシジョン ツリーおよびニューラル ネットワーク アルゴリズムでも使用されます)。 XLSX 。
テーブル ファイルの構造化データはインポートに使用できます。 Excel ワークブック (*.xlsx)。 Excel バイナリ ワークブック (*.xlsb); OpenDocument スプレッドシート (*.ods)。
どこで使われているのでしょうか?
重回帰を使用したデータ分析は次のように適用できます。
- 効果的な(コスト、時間、リソース)代替手段として」 実験の計画 「入力パラメータの最適なモードを検索します。
- 出力パラメータの測定手順が高価かつ/または時間のかかるテストによって実行される場合、出力パラメータの予備的または代替評価用。
- 意思決定に人的エラーのリスクが伴う場合の、専門家意思決定支援システム (DSS) 向け。
データモデルファイル
当社のソフトウェアは、他のコンピューターで作成され、ファイル (*.sav) に保存された、scikit-learn ライブラリのトレーニング済み多変量線形回帰数学モデルを使用できます。
連続入出力測定のための重線形回帰

図 1. 機械学習 (ML) 機能にアクセスするためのウィンドウ。メインメニュー項目[データ分析方法]にマウスを置くと、ドロップダウンメニューのリストが表示されます。

図 2. 機械学習 (ML) 関数ウィンドウ。ボタンの上にマウスを置くとツールヒントが表示され、複数の線形回帰関数に移動します。

図 3. 重回帰関数ウィンドウ。

図 4. 重回帰関数ウィンドウ。 [モデル評価用グラフの種類]のドロップダウンリストボックスで、グラフ[折れ線グラフ]を選択します。現在と予測]。

図 5. 重回帰関数ウィンドウ。 [モデル評価用グラフの種類]のドロップダウンリストボックスで、グラフ[折れ線グラフ]を選択します。現在と予測]。グラフは X 軸に沿ってスケールされます。

図 6. 重回帰関数ウィンドウ。 [モデル評価用グラフの種類]のドロップダウンリストボックスで、グラフ[重回帰係数表]を選択します。

図 7. 重回帰関数ウィンドウ。新しいデータをインポートするテーブル ファイルを選択するボタンの上にマウスを置くと、ドロップダウン ツールチップが表示されます。

図 8. 多変量線形回帰を使用して数学モデルをトレーニングするためのテーブル ファイルを選択するウィンドウ。

図 9. 重回帰関数ウィンドウ。 [モデルを保存] チェックボックスにマウスを置くと、ドロップダウン ツールチップが表示されます。 [従属変数の値を予測する:] ドロップダウン リストで必要な従属変数を選択すると、モデルは適切なアプリケーション フォルダー [SCCPython\resources\Model_AI] に自動的に保存されます。

図 10. 重回帰関数ウィンドウ。数理モデルファイルの保存に関するメッセージウィンドウが表示されます。
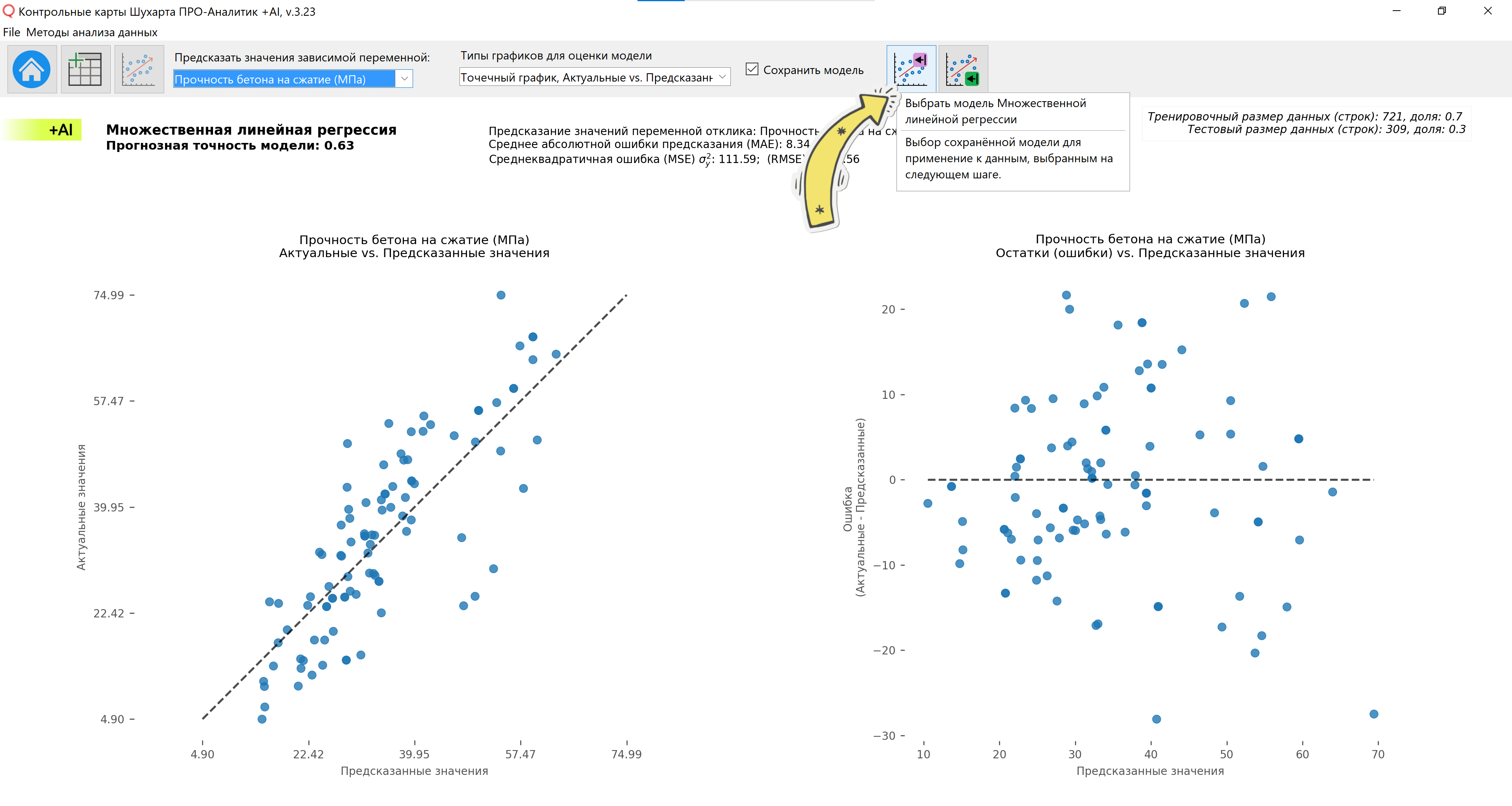
図 11. 重回帰関数ウィンドウ。ボタンの上にマウスを置くと、ドロップダウン ツールチップが表示され、保存された数学モデルを選択するためのコントロール パネルに移動します。

図 12. 重回帰関数ウィンドウ。保存された数学モデルを選択するためのコントロール パネル。選択した数学モデルのファイルへのパスの上にマウスを置くと、ドロップダウン ツールチップが表示されます。

図 13. 重回帰関数ウィンドウ。保存された数学モデルを選択するためのコントロール パネル。ボタンの上にマウスを置くと、ドロップダウン ツールチップが表示され、従属変数を予測するためのデータを含むファイルを選択するためのコントロール パネルに移動します。

図 14. 重回帰関数ウィンドウ。独立変数を含むデータを選択し、数学モデルを適用して従属変数を予測するためのダッシュボード。データ ファイルへのパスの上にマウスを置くと、ドロップダウン ツールチップが表示されます。インジケーターの値を予測するには、データ ファイル内のシートが選択されます。

図 15. 多重線形回帰関数ウィンドウ。独立変数を含むデータを選択し、数学モデルを適用して従属変数を予測するためのダッシュボード。[結果を予測] ボタンの上にマウスを置くと、ドロップダウン ツールヒントが表示されます。

図 16. 重回帰関数ウィンドウ。 「結果を予測」ボタンをクリックすると、前のステップでインポートしたデータにモデルが適用され、操作が完了すると通知ウィンドウが開き、予測値が Excel ファイルに保存されます。
インポートされたデータに、[男性、女性] などのカテゴリ値を持つ説明変数列が 1 つ以上含まれている場合、自動ワンホット エンコーディング手順が実行され、データが新しい数値コード列 [0, 1] に変換されます。ホット エンコードされたデータは、新しいシートの元の [xlsx] ファイルに保存されます。
線形回帰法を使用した数学モデルの精度が低い理由
- 線形回帰の仮定の不一致: 線形回帰では、特徴とターゲット変数の間の線形関係が仮定されます。非線形関係が存在する場合、線形回帰の精度が低くなる可能性があります。
- 間違った特徴の選択: 正しい特徴を選択することは、線形回帰モデルの精度にとって非常に重要です。不適切または無関係な特徴がモデルに含まれている場合、モデルの精度が低下する可能性があります。
- データが不十分: モデルが少量のデータでトレーニングされると、精度が低くなる可能性があります。トレーニングに使用できるデータが多いほど、線形回帰モデルの精度が高まります。
- エラーの独立性の仮定の違反: 線形回帰では、モデル エラーが独立しており、同一に分布していることが必要です。この仮定に違反すると、モデルの精度が低くなる可能性があります。
- フィーチャの多重共線性: 多重共線性は、モデル内のフィーチャが互いに高度に相関している場合に発生します。これは線形回帰の精度に影響を与える可能性があります。
- フィーチャの不適切な標準化: フィーチャが標準化されていない場合、スケールの異なるフィーチャがモデルに不均一に寄与する可能性があり、精度の低下につながる可能性があります。