代替データ (属性、カウント) の管理図、P チャート、NP チャート、C チャート、U チャート、または個別の値の 1 つの XmR チャート?
「p チャート、np チャート、C チャート、または u チャートを使用する場合の難しさは、二項モデルとポアソン モデルのどちらがデータに適切であるかを判断するのが難しいことです。」
Donald Wheeler の記事「What about the p-chart? When you use the p-chart, np-chart, C-chart, and u-chart control charts for Alternative data (counts)?」の翻訳を紹介します。 / Donald J. Wheeler、記事: 「p チャートについてはどうですか? カウント データに特殊チャートである p チャート、np チャート、c チャート、および u チャートをいつ使用する必要がありますか?」 [31]
翻訳とメモ: AQT センター科学ディレクター セルゲイ・P・グリゴリエフ 。
記事への自由なアクセスは、記事に含まれる資料の価値を決して減じるものではありません。
コンテンツ
すべてのカウントデータベースの管理図は離散値管理図です。量を扱う場合でも分数を扱う場合でも、期間ごとに 1 つの値を受け取り、値を受け取るたびにグラフ上に点をプロットしたいと考えます。これが、個別の値と移動範囲の XmR 管理図を構築するアプローチが発見される前であっても、カウントベースのデータ用に 4 つの特定の管理図が開発された理由です。これら 4 種類のコントロール カードは、p カード、np カード、C カード、および u カードです。この記事では、カウントベースのデータを含むこれらの管理図やその他の特殊な管理図をいつ使用するかについて説明します。
これらの特別な管理図の最初のものである p 管理図は、1924 年にウォルター シューハートによって作成されました。当時、2 点のスライディング レンジを使用して一連の個別の値の分散を測定するというアイデアは、まだ生まれていない(W. J. ジェネットは 1942 年にこのアイデアを提案した)。したがって、シューハートが直面した問題は、カウントに基づいて離散値のプロセス動作図を作成する方法でした。データを現在の記録としてプロットすることはでき、平均をその現在の記録の中心線として使用することはできましたが、障害となるのは、分散を測定して正規の変動を除外する方法でした。離散値を使用する場合、サブグループ内の変動を利用する方法はないと考えましたが、利用可能なデータの例外的な分散によって増大するグローバル標準偏差統計を使用するよりも賢明であると考えていました。したがって、確率モデルに基づいた理論的な管理限界を使用することにしました。
単純な計数データの古典的な確率モデルは二項モデルとポアソンモデルであり、シューハートはこれらのモデルの両方に位置パラメータの関数である分散パラメータがあることを知っていました。これは、データから得られた平均の推定値を分散の推定にも使用できることを意味します。したがって、位置統計だけを使用して、中心線と 3 シグマ距離の両方を推定できました。
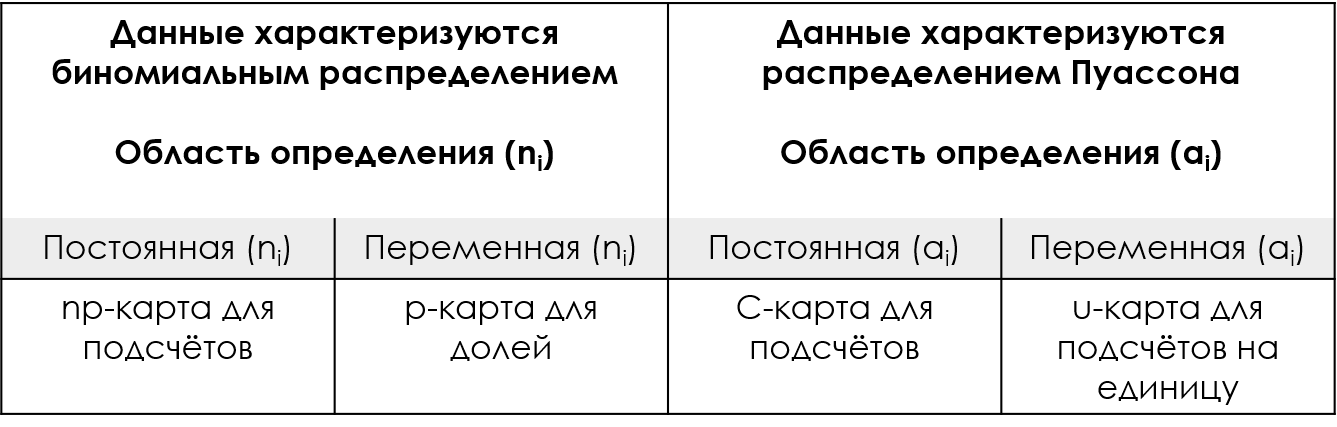
図 1: これらの計算のためのシューハートの特別な管理図。
位置と分散の両方を特徴付けるために平均を二重に使用するということは、p 管理図、np 管理図、C 管理図、および U 管理図には、平均と分散の間の理論的な関係に基づく管理限界があることを意味します。
したがって、すべての特殊管理図は理論上の管理限界を使用していると言えます。二項分布またはポアソン分布を使用してカウントを合理的にモデル化できる場合、離散値管理図に対して適切な管理限界を取得できます。
近年、多くの教科書や規格では、二項モデルまたはポアソン モデルの仮定が、これらの特別な管理図を使用するための主な要件であることが忘れられています。これは、二項分布またはポアソン分布として特徴付けることができない種類のカウントベースのデータが多数存在するため、問題となります。このようなデータを p 管理図、np 管理図、C 管理図、および U 管理図に配置すると、結果として得られる理論的な管理限界が不正確になります。
だから何をすべきか?理論的な管理限界の問題は、中心線と 3 シグマ距離の間の正確な関係がわかっているという前提にあります。解決策は、分散の別の推定値を取得することです。これは、XmR チャートが行うことです。平均は位置を特徴づけ、個々の値の X マップの中心線として機能しますが、mR チャートの移動平均範囲は、分散を特徴づけ、X マップの 3 シグマ距離を計算するための基礎として機能します。
したがって、専用のカウント管理チャートと個別値および移動範囲の XmR チャートの主な違いは、スリーシグマ距離の計算方法です。参照 p チャート、np チャート、C チャート、および u チャートは、X マップと同じ現在のエントリと基本的に同じ中心線を持ちます。ただし、スリーシグマ管理限界の計算に関しては、専用の管理図は推定された理論的関係を使用して理論値を計算しますが、XmR 管理図はデータに存在する変動を実際に測定し、経験的な管理限界を構築します。
カスタム コントロール カードと XmR カードを比較するために、3 つの例を使用します。最初のデータは、図 2 に示すデータを使用します。これらの値は、毎月「予定通り」に閉鎖された口座の数を追跡する会計部門から取得されます。表示されている数は、35 件の閉鎖 (定義の等しい面積) あたり、時間通りに完了した月間閉鎖数を表します。
米。 2: 35 アカウントごとの月次の期限内に閉鎖されたアカウント数の X カードおよび np チャート。
赤い点線は X マップの上限と下限の管理限界、青は P 管理図です。
ここで、np 管理図と個々の値の X マップの両方を計算すると、ほぼ同じ管理限界が得られます (管理上限値 36.8 は、オンタイム閉鎖 35 の最大値を超えているため表示されていません)。ここで、これらのカウントは二項分布によって適切にモデル化されているように見えるため、2 つのアプローチは本質的に同じです。これがいつ起こるかを認識するのに十分なスキルを持っていれば、np カードがいつ機能するかを知り、それをうまく使用できるようになります。一方、二項モデルがいつ適切であるかを判断するのに十分な経験がない場合でも、XmR チャートを使用できます。ここでわかるように、np 管理図が機能する場合、X 管理図の経験的管理限界は np 管理図の理論的管理限界と同じになり、XmR 管理図の代わりに XmR 管理図を使用しても何も失われません。 np チャート。
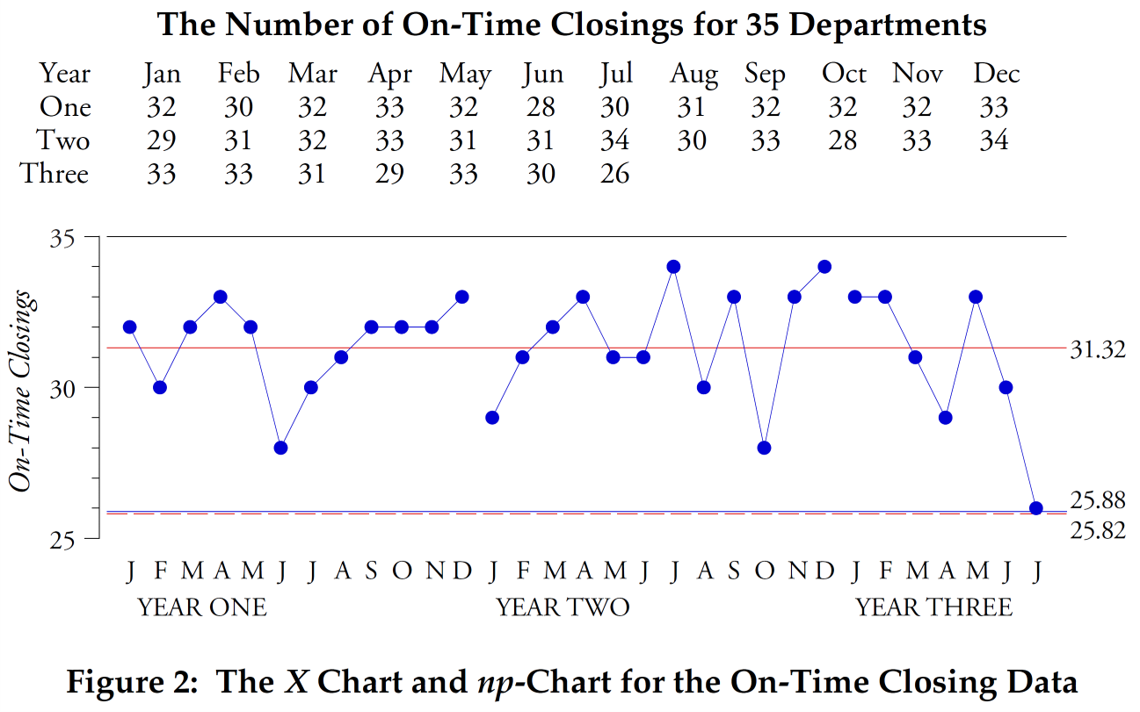
次の例では、プラントの期日通りの納品を使用します。 2 年間にわたる月ごとの納期遵守率のデータを、個々の値の X マップとこのデータの P チャートとともに図 3 に示します。
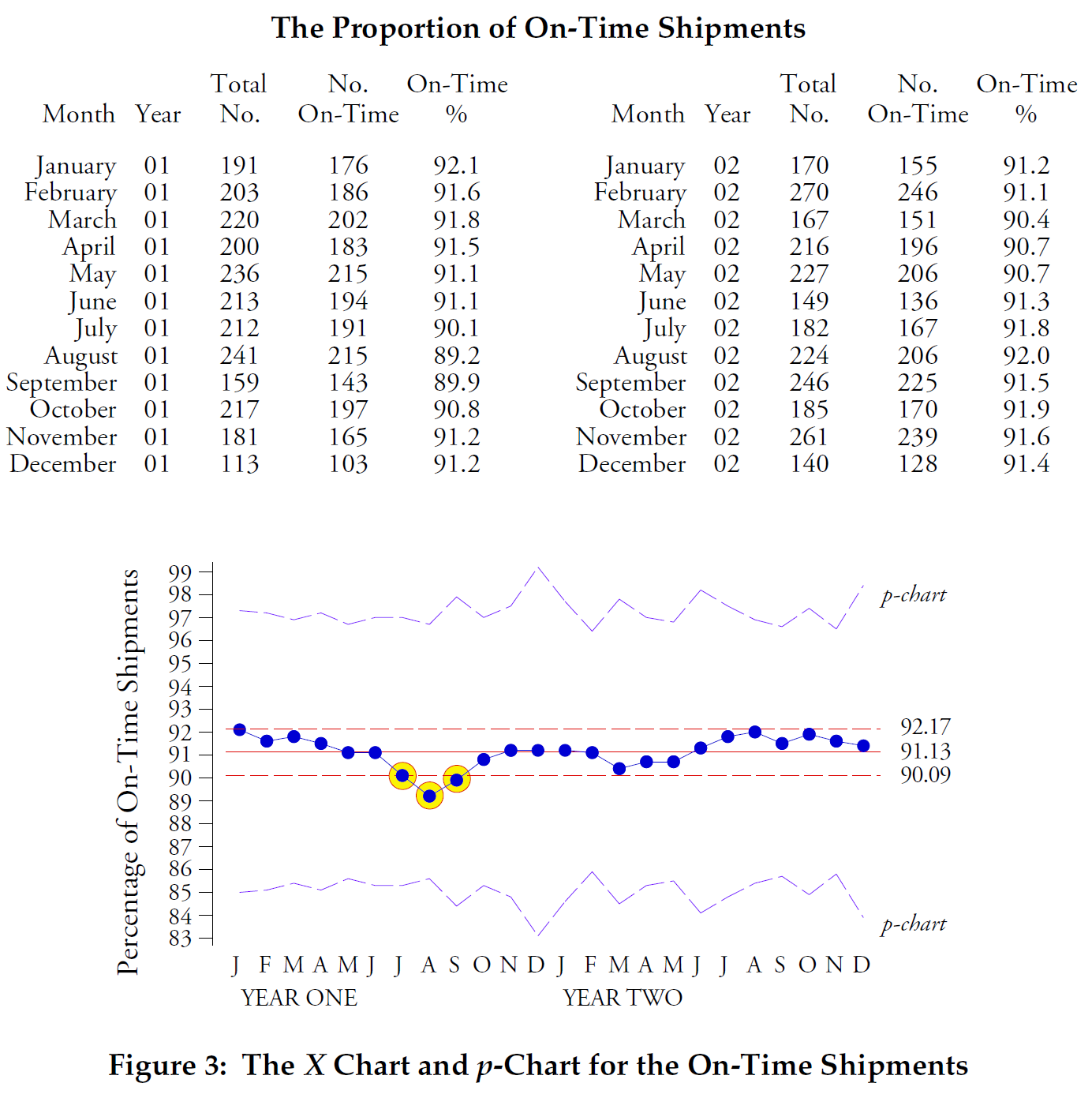
図 3: 2 年間にわたる月別の納期厳守率の X マップと P チャート。
X マップは、3 つの点が下限管理限界以下であるプロセスを示します。可変幅の P チャートの管理限界は、スライディング スパンを使用して検出される X マップの管理限界より 5 倍広いです。これらの p 管理図の管理限界を超える点はありません。 2 組の管理限界間のこの不一致は、図 3 のデータが二項条件を満たしていないことを示しています。特に、荷物が予定どおりに到着する確率は、特定の月のすべての荷物で同じではありません。二項モデルはこれらのデータには適していないため、理論的な p チャートの管理限界は不正確です。ただし、特定の確率モデルの適合に依存しない XmR 管理図の経験的な管理限界は正しいです。
最終的な比較では、図 4 のデータを使用します。ここでは、ある電子機器組立工場の入荷貨物のうち、航空貨物を使用して出荷されたものの割合を示しています。 2 つの点が可変幅 p チャートの管理限界の外にありますが、X マップの管理限界の外にある点はありません。
図 4: 個々の値の X マップと航空貨物を使用した出荷の割合の P チャート。
図 4 は、品目を数える「機会の領域」が過度に大きくなった場合に何が起こるかを示したものです。二項モデルでは、特定の期間内のすべての要素が、カウントされる属性を所有する機会が等しいことが必要です。この要件はここでは満たされていません。毎月何千件もの荷物が発送されるため、荷物が航空便で送られる可能性はすべての荷物で同じではありません。したがって、二項モデルは適切ではなく、二項モデルに依存する理論的な p 管理図の管理限界は不正確です。 X マップ管理限界は、ここでは P 管理図管理限界の 2 倍の幅であり、このデータの位置と広がりの両方を正確に特徴づけており、使用する正しい管理限界です。
したがって、p チャート、np チャート、C チャート、または u チャートの使用の難しさは、二項モデルとポアソン モデルのどちらがデータに適切であるかを判断するのが難しいことです。図 3 と図 4 からわかるように、特殊な管理図の基本条件を怠ると、実際に重大な間違いを犯す危険があります。このため、これらの確率モデルに対するデータの適合性を評価する方法を知らない限り、アドホック管理図の使用を避けるべきです。
正しいかどうかわからない理論モデルを使用するのとは異なり、XmR 管理図はデータ内に存在する変動に実際に基づいた経験的な管理限界を提供します。これは、カウントベースのデータを含む XmR チャートをいつでも使用できることを意味します。 p チャート、np チャート、C チャート、および u チャートは離散値チャートの特殊なケースであるため、XmR チャートは適切な場合はこれらの特殊なチャートを模倣し、失敗した場合はそれらとは異なります。
可変幅の制御限界を持つ特殊な制御カードの場合、XmR-cut はカウント用の制御カードの平均定義領域に基づいて制御限界をシミュレートします。さらに、これらの比較を行うときは、基本期間に少なくとも 24 カウントがあることが望ましいと考えています。
図 5: カウントベースのデータに対する仮定のないアプローチ。
したがって、統計学の高度な学位を持っていない場合、または単にカウントを二項分布またはポアソン分布で特徴付けることができるかどうかを判断するのが難しい場合でも、カウントベースの特別なグラフの選択をテストできます。理論的な管理限界と XmR 管理図の経験的な管理限界を比較することによってデータを分析します。経験的な管理限界が理論的な管理限界とほぼ同じである場合、確率モデルは機能します。経験的管理限界が理論的管理限界と一致しない場合、確率モデルは正しくありません。
最初から XmR 管理図を使用すると、個数ベースのデータに正しい管理限界があることを常に確認できます。経験的なアプローチは常に正しいでしょう。
注 (S. グリゴリエフ)
彼の著書『統計的プロセス制御』。シューハート管理図を使用したビジネスの最適化」では、ドナルド ウィーラーは、個別値の XmR 管理図の経験的管理限界に対する計算データの離散性の影響を最小限に抑えるために必要な別の条件を定義しています。
「離散データの XmR 管理図は、平均カウント値が 1 より大きいすべての場合に作成できます。2 より大きい場合、管理限界に対する離散性の影響は無視できます。
測定結果が得られる場合、離散量を使用することが意味を成すことはほとんどないため、属性の使用は通常、間違いが数えられる状況に限定されます。ただし、「失敗」を定義するのは通常非常に困難です。
「失敗」を定義する際の主な困難は、 操作上の定義 」。
したがって、定義ドメインごとのカウントの平均が 2 未満の場合は、定義ドメインを増やしてカウントの平均を 3 以上の値にすることで、この問題を簡単に解消できます。これは、ポアソン分布を持つイベントに特に当てはまります (欠陥はカウントされ、欠陥製品ではなく、欠陥のみがカウントされますが、「非欠陥」の数はカウントされません)。
例えば
定義領域あたりの平均欠陥数が 1 に等しい生地 1 平方メートルに等しい場合、3 平方メートルの定義領域を使用して、新しい定義領域あたりの平均欠陥数を取得できます。 3平方メートルまで。チェック(テスト)用に簡単に選択できる定義エリアを使用できます。たとえば、幅1.2メートルの生地のロールの場合、3リニアメートルの定義エリアを使用できます。
必要な最小定義領域を計算するための式:
履歴データ数の平均が 3 未満の場合、
新しい最小定義領域は、現在の定義領域に係数 (k) を乗算することによって取得されます。
k = 3/履歴データ数の平均値。
新しいドメインの最小値 = k × 現在のドメイン。
結果として得られる制御に便利な最小の新しい定義領域の定義領域 (=) または (>) を選択します。
二項値 (はい/いいえ、不良品/良品、期限内/期限内) の場合、例 1 で実装されているように、XmR チャートを使用して、否定的な結果ではなく肯定的な結果の値を取得できます (図この記事の 2) と 2 (図 3) Donald Wheeler。個々の値の XmR チャートにおける二項モデル データの離散性の影響は、ポアソン モデルの場合と同じルールに従い、結果カウント (はい/いいえ) の平均が少なくとも 3 に保たれます。
注意!
スコープが異なる場合、カウントを対応するスコープの小数に変換せずに比較することはできません。それでも株価を解釈することが難しい場合は、D. Wheeler によるこの記事の例 1 のように、適時決算の管理図の例を使用して、取得した計算値を 1 つの定義領域にまとめることができます。アカウント。これを行うには、以下に示す式を使用できます。
探しているもの:
バツ 私 - 定義の一定領域に換算されたカウント数。

「すべての分数は分数ですが、すべての分数が分数であるわけではありません。分母が分子値の定義領域を表す場合、分数は分数と見なされます。」
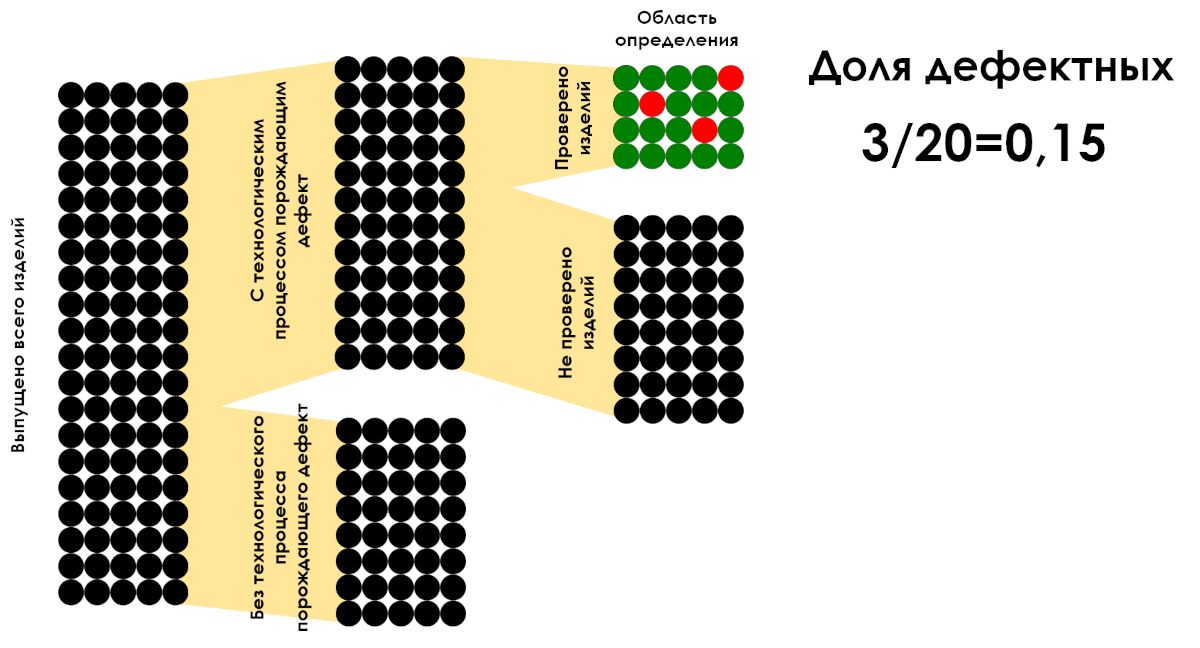
図6:定義領域ごとの不良品の割合の計算例。 3/20 の比率のみが分数になります。
この記事に記載されているすべての推奨事項に必ず従うようにしてください。 計画段階で データ収集。ほとんどの場合、データが 100% 制御の結果を表していない場合、数学を使用して定義の範囲を拡大するために利用可能な履歴データを操作すると、何が起こっているかの全体像が歪められます。