分布ヒストグラムと再現性指標 Cp、Cpk を分析するだけで十分ですか?シューハート管理図を作成して分析を始めましょう。
この資料は、AQT センターの科学ディレクターによって作成されました。 グリゴリエフ S.P.
記事への自由なアクセスは、記事に含まれる資料の価値を決して減じるものではありません。
ある研究制作会社の品質保証部門で、専門家が重大事故の原因を調査するときに使用する重要な品質指標の分布のヒストグラムを見せてもらいました。彼らの議論はむしろコーヒーのかすで占うようなものだった。この指標の製造プロセスの統計的状態については誰も知りませんでした。
米。 1: 主要な品質指標の分布のヒストグラム。
どうしてそれが重要ですか?!事故は結果であって原因ではありません。
上の図に示されている指標分布のヒストグラムは、統計的に安定した (予測可能な) プロセスと統計的に不安定な (予測不可能な) プロセスの両方の機能の結果である可能性があります。
製造部門がこのヒストグラムの部品パラメータを記録しているのであれば、なぜプロセスの統計ステータスを追跡するためにシューハート管理図が維持されていないのでしょうか?管理図は、たとえ部品の制御パラメータがまだ許容範囲内にあったとしても、部品の故障の原因となった生産プロセスの問題をできるだけ早く報告します。問題の具体的な原因が特定され、修正されるまで、生産担当者は生産プロセスを停止する理由があります。プロセス障害の影響を受けた期間に製造された部品については、たとえそれらの部品が公差範囲内にあったとしても、さらに合格するか不合格にするかを決定する必要があると私は強調します。統計的に不安定な (予測不可能な) 状態にあるプロセスで製造された部品は均一ではなく、大きく異なります。均一性を決定するための許容限界は適用されません。特に重要な部分については、これを理解することが重要です。
プロセスを改善するために、それに関連する 2 つの相反するタイプの尺度のどちらを選択するかは、分析されたプロセスが位置する統計的状態に依存します。詳細な説明は「」の記事を参照してください。 変動の性質 」。
以下は、このケースの原因となった密度ヒストグラムの解釈の問題についてのエドワーズ・デミングの説明です。
「統計学のコースは、多くの場合、分布とその比較の研究から始まります。授業や書籍では、分析目的 (プロセス改善など) で分布や平均値、標準偏差、カイ 2 乗値、t - の計算を学生が行うことについて警告されていません。統計などは、統計制御の状態にあるプロセスからデータが取得されない限り役に立ちません。
したがって、データを調べる最初のステップは、それが統計的制御の状態で取得されたかどうかを理解することです。データを分析する最も簡単な方法は、ポイントを出現順に並べて、データによって形成された分布から何かを学べるかどうかを確認することです。
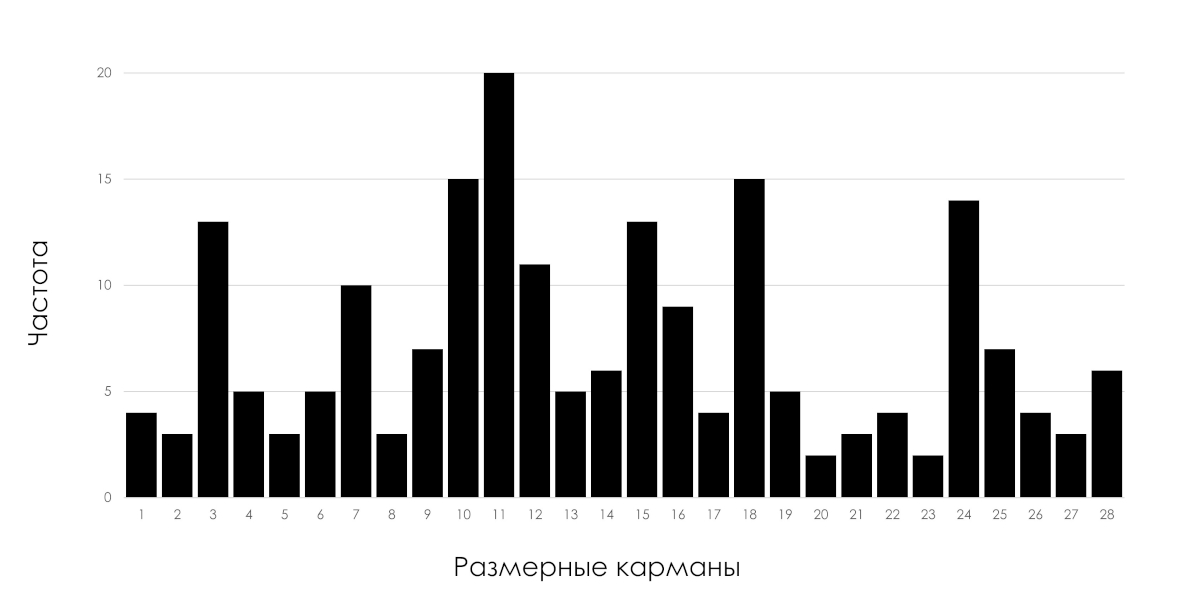
例として、最高の特性を持つように見えるが、役に立たないだけでなく、誤解を招く分布を見てみましょう。図2では、ある機種のカメラに使用されている同種のバネ50個の測定結果の分布を示しています。スプリングは 20g の力で引っ張って測定しました。
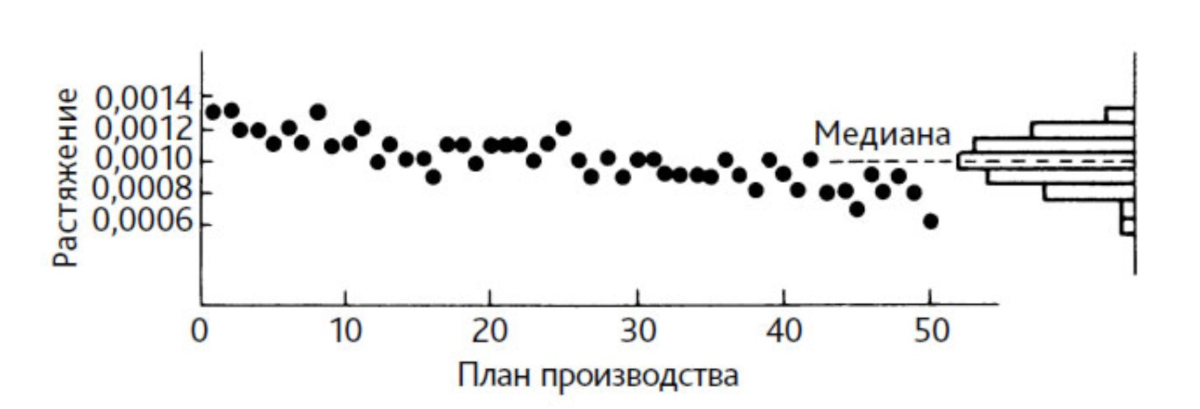
米。 2. 製造順にテストされた 50 個のばねの分布ヒストグラムを含むプロセスの散布図。出典: [2] エドワーズ・デミング、著書『危機の克服』、224-225 ページ
データ(図2)は製造時間を考慮しないと対称的な分布になりますが、ばねの製造順に並べると無駄な分布となることがわかります。たとえば、分布からは、完成したスプリングがどのような公差に該当するかは分かりません。その理由は、識別可能なプロセスがないためです。
分布はかなり対称的で、許容範囲内にあるようです。プロセスが満足のいく状態にあると結論付けたくなります。ただし、製造時期の順に引張値を並べると減少傾向が見られます。
製造工程または測定器に異常がある。図 2 に示す分布を使用しようとしても無駄です。たとえば、特定の分布の標準偏差を計算しても、予測に使用できる値は生成されません。プロセスが不安定であるため、プロセスについては何も書かれていません。
したがって、データを分析するにはデータを確認する必要があるという非常に重要な教訓を学びました。ポイントを生産順またはその他の合理的な順序に配置します。問題によっては、単純な散布図が役立ちます。
誰かがこの分布を使用してプロセス再現性のメトリクスを計算しようとした場合はどうなるでしょうか?彼は逃れるのが難しい罠に陥ることになる。プロセスが不安定です。再現性はまったくありません。
分布 (ヒストグラム) は、プロセスの蓄積されたデータを示すだけであり、その再現性については何も述べていません。プロセスは安定している場合にのみ再現可能です。プロセスの再現性は、管理図の使用によって実現および確認されますが、分布自体によっては実現されません。すでに見たように、単純なプロセス チャートでもプロセスの再現性がわかります。」
私たちの中で ソフトウェア 個々の値の分布のヒストグラムは、ヒストグラムの下の散布図によって補完されます (図 3)。これは、ヒストグラムによって隠されたプロセスに関する情報を示し、データ層別化の最良の基礎となります。
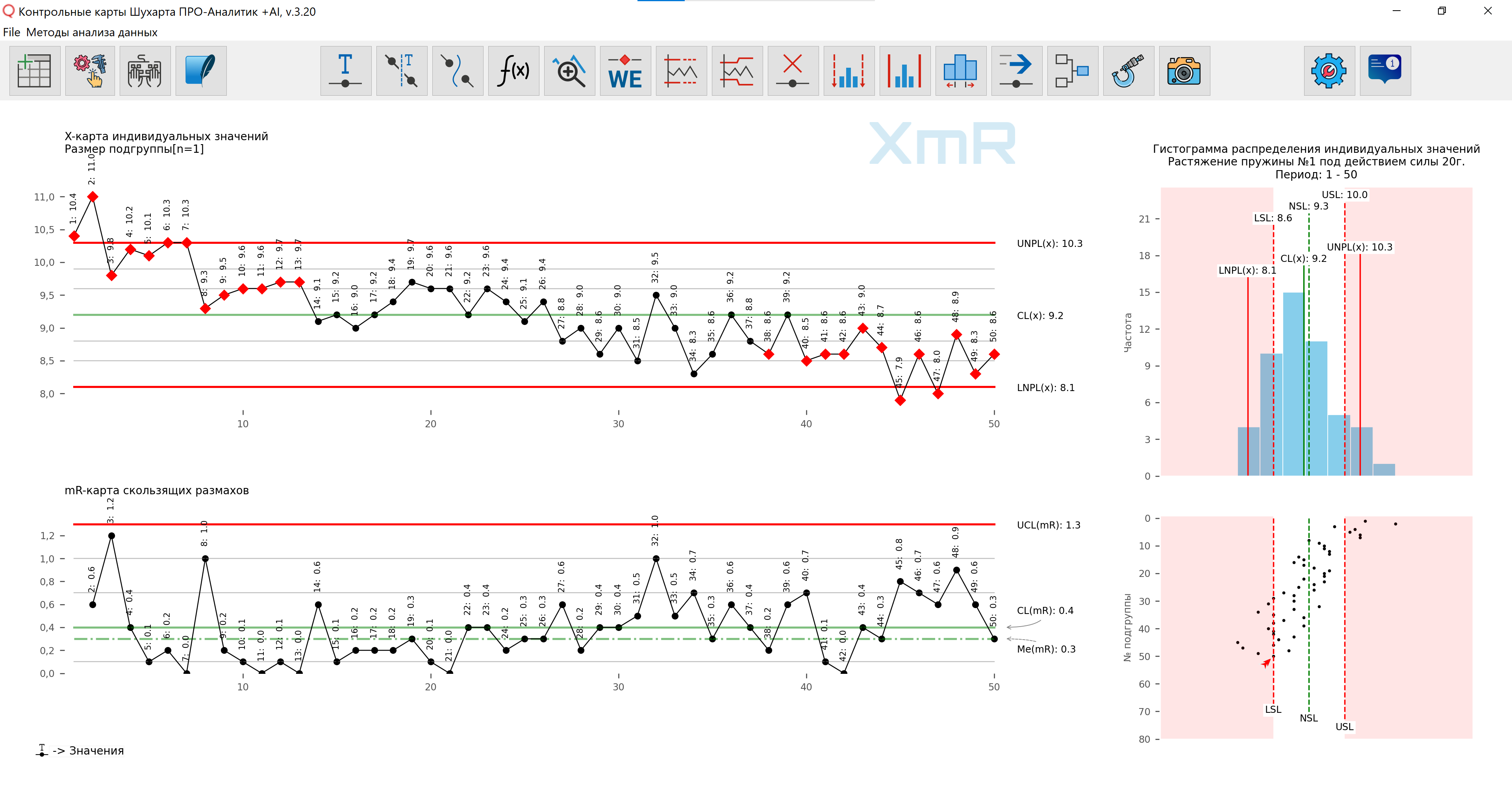
図 3. 開発した図を使用して作成した図 ソフトウェア 。
製品の出力、つまり出力の時系列順に、データに応じて個別の値と移動範囲の単純な XmR 管理図を構築する必要があります。 サンプル測定の順番ではありません 。
よくある間違い!検査のために受け取った製品は共通の山に移され、検査官は最初に取り出して同じ順序でメモを取るのが便利であるという原則に従って製品を選択します。製品出力の時系列順序が失われます。
事前にこのデータを収集し、便利な方法で生産順序をマークしてください。さらに、ヒストグラム内のデータは、さまざまなタイプの変動源 (マシン、オペレーター、監督者、原材料のバッチなど) や、タイプ内の変動源 (たとえば、マシン 1、マシン 2、マシン-3)。シューハート管理図は、変動源の混合からのデータの分析に適していますが、会計に利用できる変動源に関する情報を使用する場合 (変動源のコンテキストで管理図を構築する場合)、より多くの情報を得ることができます。その結果、改善の機会がさらに増えることになります。繰り返しになりますが、このデータは必ず事前に収集してください。また、データのトレーサビリティを確保する手順に注意すると、因果関係の特定が大幅に容易になります。
次のレベルでは、サブグループの平均と範囲の XbarR チャートを使用してプロセスの出力を分析できます。
したがって、Shewhart XbarR コントロール カードの場合は、次のものが必要になります。 データをサブグループに合理的にグループ化する 変動の種類と原因を考慮に入れます。たとえば、特定の演算子に対するインジケーターの依存性を分析するには、データをサブグループにグループ化して、異なる演算子からのデータが 1 つのサブグループに分類されないようにする必要があります。
マネージャーはよく悪名高い「ヒューマンファクター」に言及し、企業の問題の大部分を説明します。もちろん、すべての人は互いに異なります。そうでないはずがありません。しかし、人々の仕事を分析するとき、さまざまな従業員と経営陣が構築したシステムとの相互作用の結果を観察することになり、プロセスの成果に対するシステムの影響は個人的な影響よりもはるかに大きいことを思い出していただきたいと思います。独自の絵の具、ブラシ、キャンバスを所有するアーティストでない限り、個々の従業員の貢献。
探究心のある人向け。
ヒストグラム (一般化) の使用にはもう 1 つの落とし穴があります。それは、個々の値が入るヒストグラム ポケット (列幅) のサイズです。右のポケットに入った測定値とわずかに異なる測定値が、最終的に左のポケットに入ってしまうことがあるかもしれません。許容範囲内および許容範囲を超えた製品でも同じことが起こります。定義を参照してください。 タグチ品質損失関数 。私は田口氏のアプローチをこのケースに適応させました。したがって、ヒストグラムの 1 つのポケット内では、すべての個々の値が同じ頻度を追加し、列の高さが増加します。値がポケットの境界のわずかに外側にある場合、それらはそれぞれ右または左のポケットに入ります。しかし、1 つのポケットに入る値間の差は、隣接するポケットの共通の境界にある値間の差よりもはるかに大きくなります。したがって、ヒストグラムは便利ですが一般化するツールであり、隣接するバーを比較する人は簡単に誤解される可能性があります。さらに、ヒストグラム バーのサイズはヒストグラム ポケットのサイズに大きく依存します。これは、同じデータ系列に対して異なるポケット サイズのヒストグラムを作成することで簡単に検証できます。当社のソフトウェアは、離散データを使用してこれらの簡単な実験を行うのに役立ちます。 カスタム ヒストグラム ポケット サイズの設定 、連続値の場合は関数: X 軸と Y 軸に沿ったヒストグラム プロットの拡大縮小 。
再現性指標 Cp、Cpk
予測できないプロセスの再現性指標 Cp と Cpk を計算することは無意味です。予測できないプロセスは、定義上、再現できません。
統計的に管理された状態にあるプロセスであっても、再現性指標は Cp、Cpk のペアでのみ使用する必要があります。そうしないと、それぞれの指標に誤解されやすくなります。ヒストグラムの形で追加のグラフ表示を行わずに再現性指標の実際的な意味を理解することは、分析者と分析者がそれらを提示しようとしている人々に不必要な認知的負荷を与えることになります。
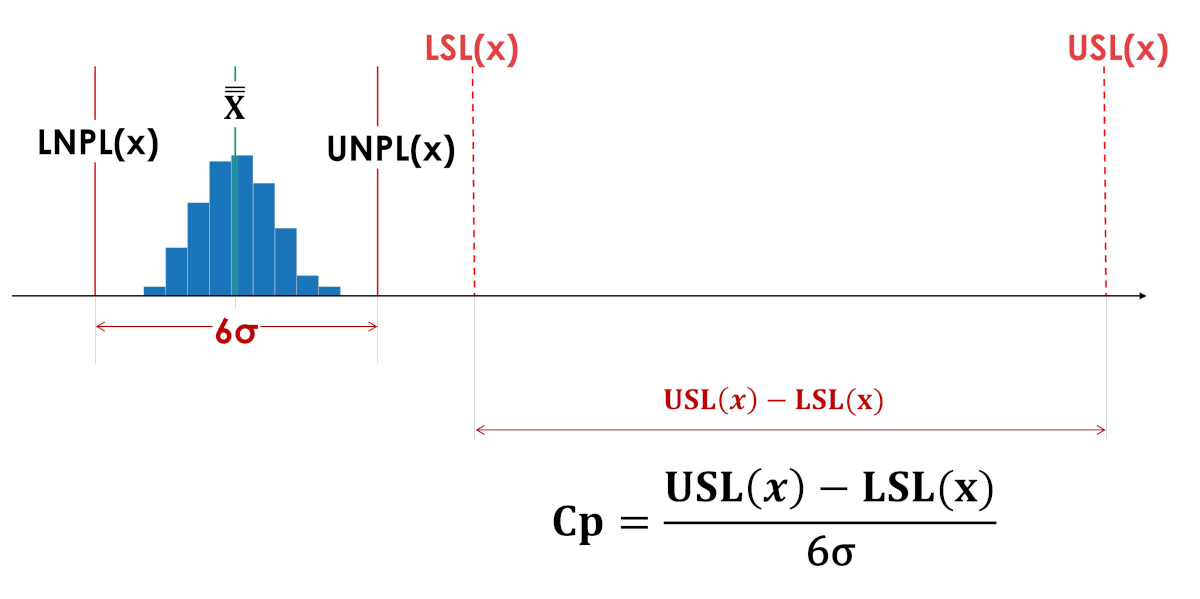
居住空間指数 (Cp) は、プロセスが許容範囲に対して相対的にどこに位置するのか、許容範囲の内側または完全に外側にあるのかを示しません。図 3 と図 4 の居住空間指数 Cp は同じ値です。
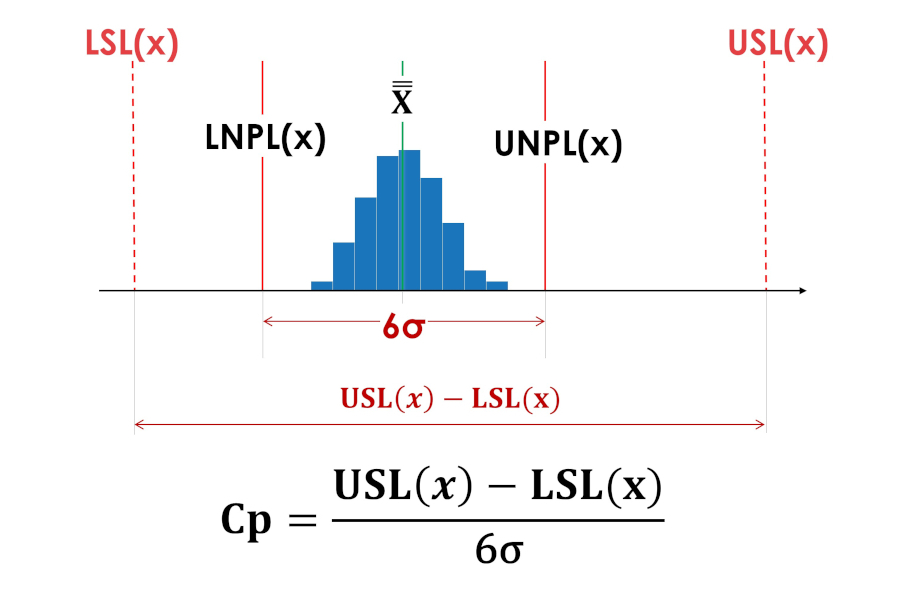
米。 3.実際のプロセス再現性の指標Cp(プロセスバイタルスペース指数)。 LSL(x) - 許容差の下限。 USL(x) - 許容上限。 LNPL(x) - プロセスの下位自然境界。 X - プロセス平均の平均。 UNPL(x) - プロセスの自然上限。
米。 4. プロセスが許容限界を超えて人為的にシフトされます。
センタリングインデックス Cpk は、公差フィールドの中心からのオフセットの側のアイデアを与えないため、プロセスを改善するための重要な情報が隠蔽され、値が公差の中心と一致しない場合は意味がありません。フィールド (非対称許容値フィールド)。
図 5 と図 6 の中心性インデックス Cpk は同じ値を持ちます。
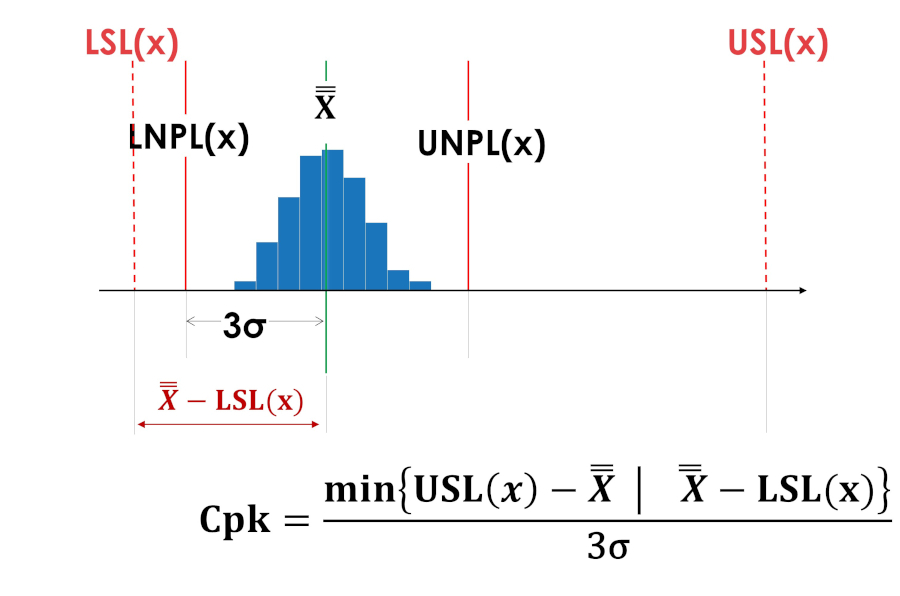
米。 5. プロセスのセンタリング指標 Cpk が公差フィールドの下限にシフトしました。
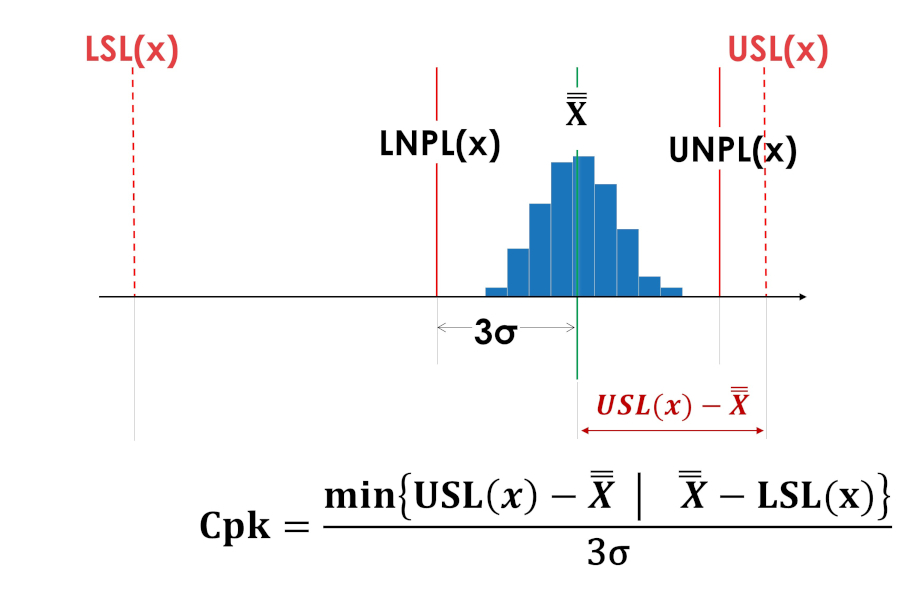
米。 6. プロセスのセンタリング指標 Cpk が公差フィールドの上限にシフトしました。
そして、繰り返しますが、プロセスとそれを改善するために何をする必要があるかについて、誰にでも理解できる、より有益な情報が、単純なグラフィカルな方法によって提供されます。シューハート管理図、分布ヒストグラム、管理値を補足する単純なドットプロットです。許容限界。
たとえば、次のような再現性指標値が告げられたと想像してください。図 7 に示すグラフを表示する代わりに、Cpk=0.9 を使用します。どの情報をより簡単に、より早く認識できるでしょうか?プロセスのより完全な全体像を得るには、どのような形式の情報伝達が必要ですか?
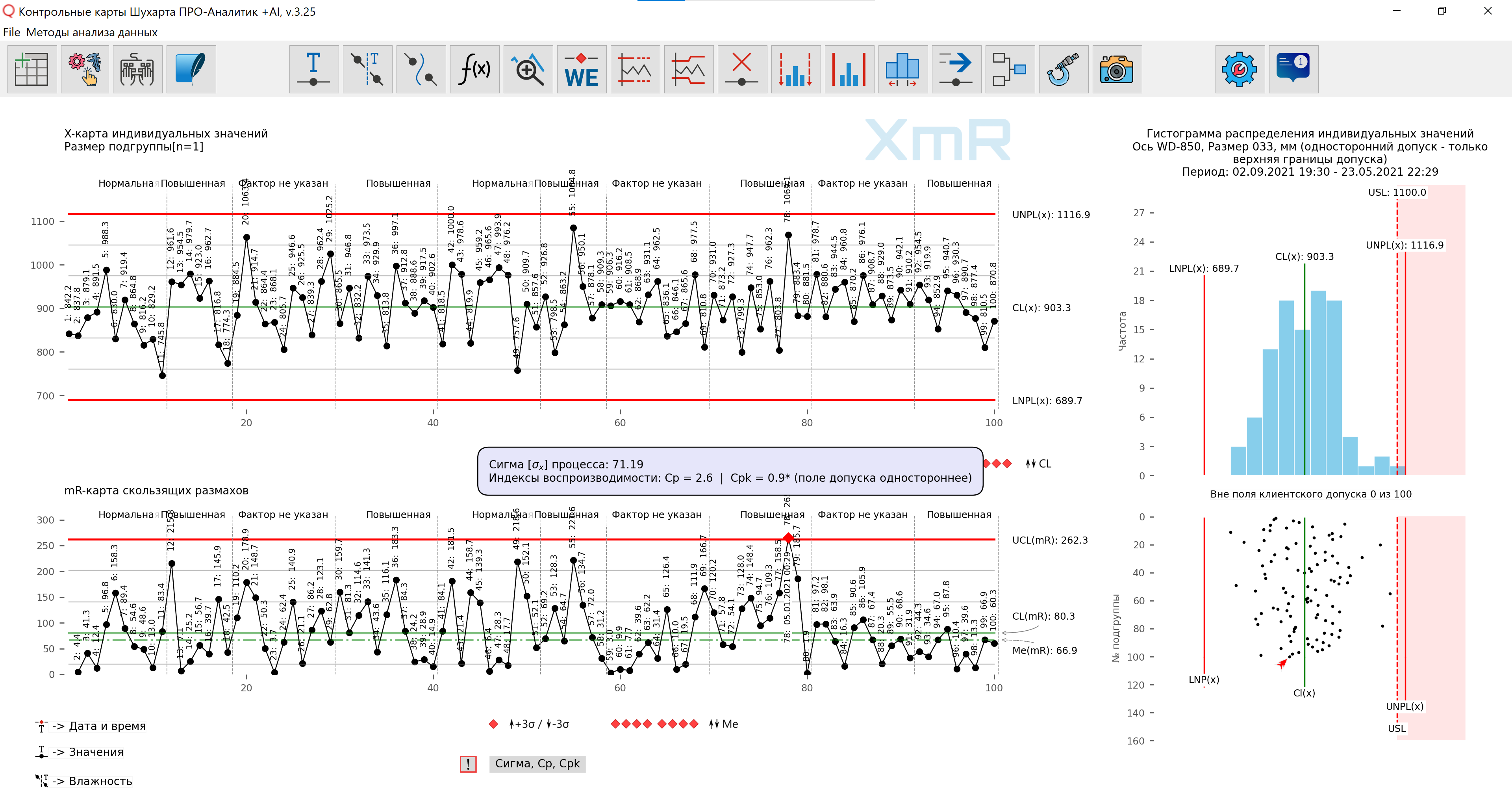
米。 7. どの情報をより簡単に、より早く認識できますか?プロセスのより完全な全体像を得るには、どのような形式の情報伝達が必要ですか?